Filemaker Maceraları
Hakkında
Ful Kontak
Search
L33T GAKKO
calimelo ·
Posted on
29 Mayıs 2021
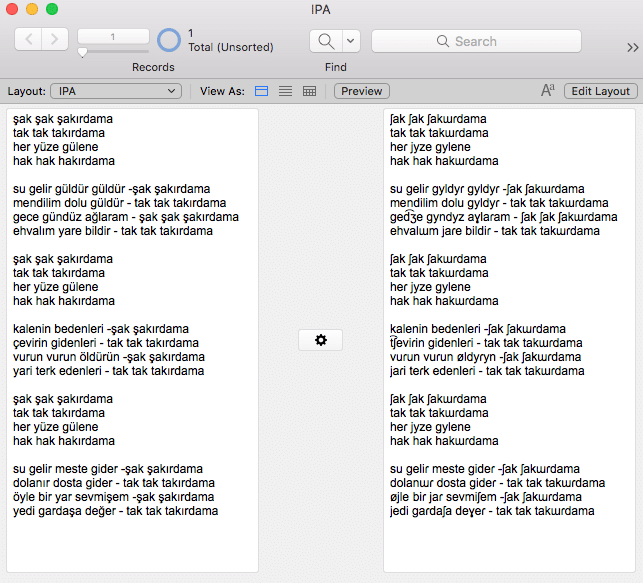
IPA
calimelo ·
Posted on
3 Mayıs 2021
6 Eylül 2023
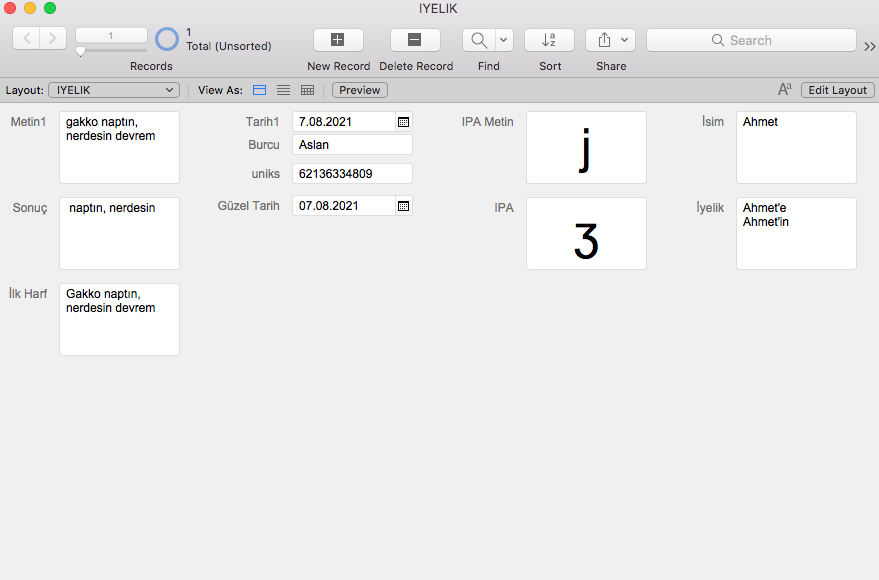
İyelikdir
calimelo ·
Posted on
3 Mayıs 2021
6 Eylül 2023
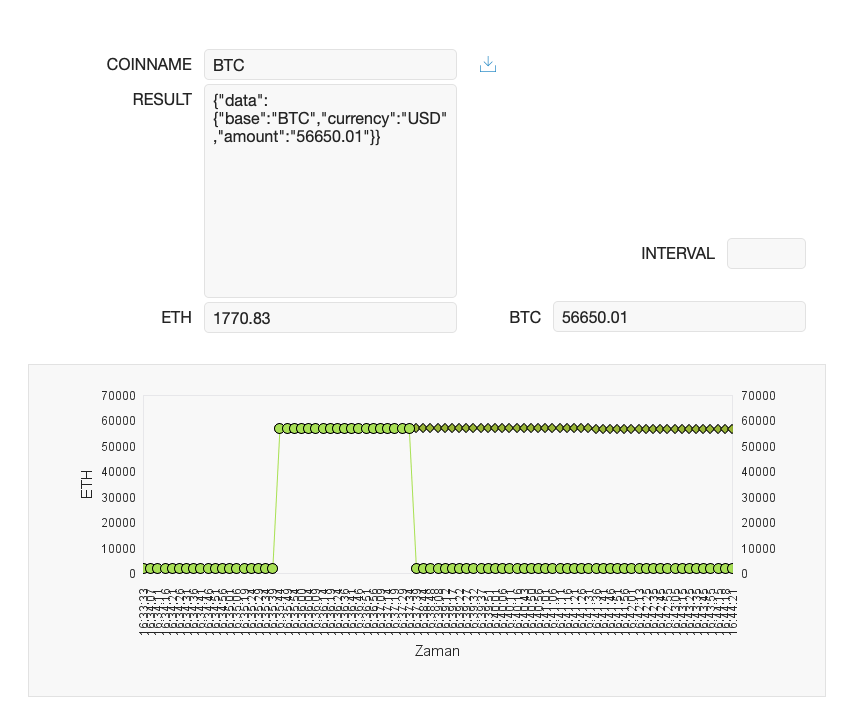
Bit mi Coin?
calimelo ·
Posted on
23 Mart 2021
6 Eylül 2023
Prezi Gakko
calimelo ·
Posted on
23 Mart 2021
6 Eylül 2023
Copy-Paste
calimelo ·
Posted on
10 Mart 2021
6 Eylül 2023
Değiştir
calimelo ·
Posted on
1 Şubat 2021
6 Eylül 2023
Eve Kaç Dakka?
calimelo ·
Posted on
23 Ekim 2020
6 Eylül 2023
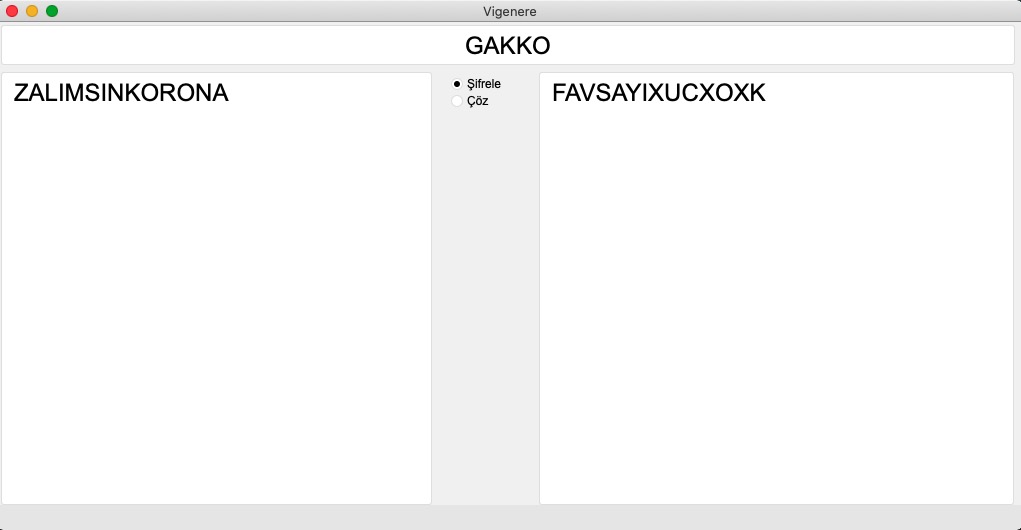
Vigenere Gakko
calimelo ·
Posted on
26 Eylül 2020
6 Eylül 2023
DEPREM
calimelo ·
Posted on
25 Temmuz 2020
6 Eylül 2023
Yazı gezinmesi
1
2
3